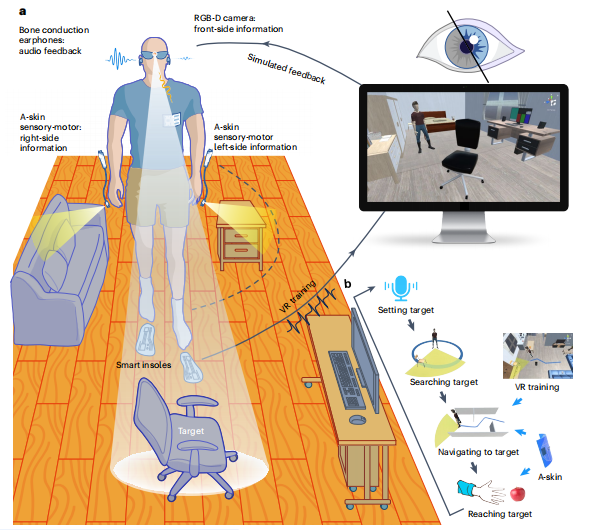
触耳寻路:视障人士导航AI系统
全球有超过2.5亿视障人士,中国的这一数字达到1700万。在城市的大街小巷,视障人士们依靠白手杖探路,却只能感知脚下约一米范围的地面,人行道上杂乱停放的共享单车、突然窜出的行人、地铁站复杂的入口不亚于荆棘遍布。而头顶的树枝、胸前的栏杆、侧面驶来的电动车,这些危险更是在白手杖的盲区。近年来,科技界不断尝试用新技术改善这一困境。智能手杖通过超声波传感器扩展了探测范围,但仍局限于前方狭窄的扇形区域;GPS导航应用如Soundscape提供语音导航,却无法识别临时障碍物,在室内和高楼林立的城市中定位精度大打折扣;BeMyEyes等视频协助应用依赖志愿者的实时帮助,但需要稳定的网络和他人的时间配合。即便是被认为是最可靠的导盲方式,训练有素的导盲犬,全国也仅有400多只服役,培训周期长达2年,成本超过20万元。
这些传统和半智能化辅助工具的局限性,让大多数视障者的活动范围被严重压缩,让大多数视障者的活动范围被严重压缩。
2025年4月,上海交通大学的研究团队在国际顶级期刊发表了一项研究成果:一套将视觉信息实时转换为听觉和触觉反馈的AI导航系统。这套系统将视觉世界翻译成视障者更容易理解的声音提示和触觉震动,构建起一张动态的感官导航地图,让视障人士通过听和摸来感知原本需要看见的世界。
这套被称为多模态可穿戴视觉辅助系统的设备,外观上并不复杂:一副重约195克的智能眼镜、一对轻巧的智能手环,以及一个骨传导耳机。

要理解这套AI导航系统如何工作,我们首先需要理解一个基本问题:视觉信息的本质是什么?
当我们看到前方有一张桌子时,大脑实际上在处理什么信息?是桌子的颜色、形状、大小,更重要的是它的空间位置:距离我们多远、在哪个方向、占据多大空间。对于导航来说,这些空间信息才是关键。
研究团队正是抓住了这一点。他们没有试图让视障人士看见完整的视觉世界,而是提取出导航所需的核心空间信息,然后用听觉和触觉重新编码。这套系统的眼睛是一个RGB-D深度相机。RGB我们都熟悉,就是相机拍摄的彩色照片。那个D代表Depth(深度),是整个系统的关键。
深度相机是如何测量距离的?它使用了一种巧妙的方法:结构光。可以想象这样一个场景:在完全黑暗的房间里,拿着手电筒照射墙壁。如果墙壁是平的,光斑是圆形的;如果墙壁是斜的或者凹凸不平的,光斑就会变形。通过分析光斑的形变,你就能推断出墙壁的形状和距离。
深度相机的原理类似,光点打到物体上会产生不同程度的变形。相机内部的传感器捕捉这些变形,通过复杂的计算,最终得出每个点的精确距离。而在深度图上,每个像素不再代表颜色,而是代表距离。通常用颜色来表示:暖色代表近,冷色代表远。
但这只是原始数据。
在日常行走中,我们的大脑在不断处理两类信息:识别(这是什么)和规划(该怎么走)。AI系统也必须完成这两个任务。
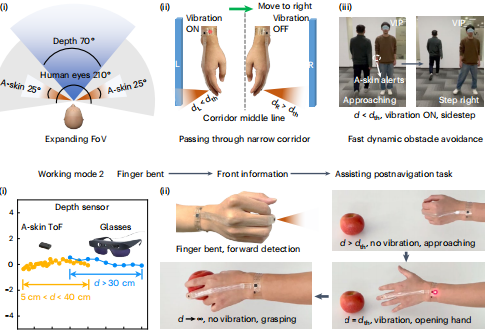
第一个任务是识别物体。系统使用了YOLOv8n神经网络,专门优化到只识别21类最关键的物体。这里有个细节很有意思:研究团队发现,导航时最大的挑战不是物体识别不准,而是识别角度的局限。视障人士往往保持头部朝前,导致很多危险来自视野边缘。因此,系统特别强化了全方位检测:无论椅子出现在正前方还是侧面150度,都能保持相同的识别率。
而第二个任务,判断哪里能走,才是真正的技术难点。
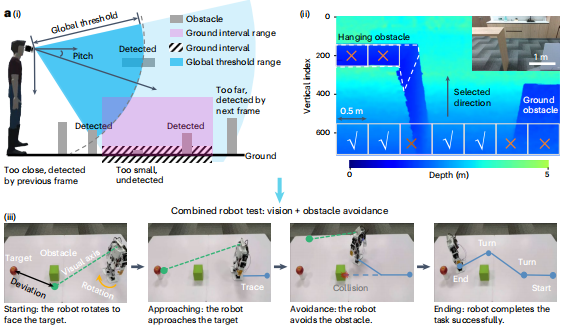
研究团队最初尝试用全局阈值法,设定一个距离阈值,比如3米内的所有物体都算障碍物。这对检测高处的障碍物很有效。但当用户低头看路时,相机随之下倾,3米的检测范围会投射到地面上,把正常地面也识别成障碍物。而如果把阈值设置得太小,又会漏掉远处地面上的低矮障碍物,比如一块砖头、一个浅坑就可能会成为漏网之鱼。
研究团队意识到,在深度图像中,正常的平坦地面有一个数学规律。站在一条笔直的道路上向前看,近处的地面在视野的下方,远处的地面逐渐升高到地平线。这种升高遵循一个可预测的曲线。系统会实时计算这条理想地面曲线。任何偏离这条曲线的点都可能是障碍:高于曲线的点?可能是凸起的石块或台阶。低于曲线的点?可能是凹陷的坑洞。曲线突然断裂?可能是路缘或墙壁。
这种方法能自适应不同情况:无论是仰头还是低头,是走上坡还是下坡,系统都能动态调整理想曲线,确保检测的准确性。
于是最终方案是让两种方法各司其职:
全局阈值法负责天空区域,专门捕捉悬空的危险
地面间隔法负责地面区域,不放过任何绊脚石。
在实际测试中,这种双重保护将障碍物检测率提升到了95%。通过这两个算法的配合,系统实现了从地面到头顶的立体防护网。整个检测过程在200毫秒内完成,这个响应可比眨眼还快。
但这只是第一步,接下来的挑战是:如何把这些复杂的空间信息,转化成视障人士能够直观理解的信号?
把视觉信息转换成声音,这个想法并不新鲜。早在1960年代,就有人尝试把图像转换成不同音调的声音。但这些早期尝试都失败了,原因很简单:信息超载。如果把眼前的每个物体都变成一种声音,几十种声音同时响起,结果只会是一片噪音。
研究团队采用了完全不同的思路:不是翻译所有信息,而是只传递最关键的导航指令。研究团队对比了空间化提示音、3D环境音和语言指令三种方式,结果是最简单的提示音效果最好,平均定位误差只有5度。语言指令虽然信息量大,但需要大脑先理解词义再转化为行动,这个过程需要500毫秒以上。而空间化提示音几乎不需要思考,它顺应了大脑处理声音的自然方式,几乎是本能反应。
但声音有个致命弱点:它是线性的,同一时间只能传递一条信息。当左右两边同时有危险时怎么办?这时候就需要触觉了。
智能手环会当侧面障碍物距离小于设定阈值时,相应一侧的手环就会振动提醒。左边有障碍,左手环振动;右边有障碍,右手环振动。使用者可以根据自己的需求设定触发距离。于是。听觉负责告诉往哪走,触觉警告离障碍物有多近;前方信息归听觉管,两侧信息归触觉管,两种信号互不干扰。
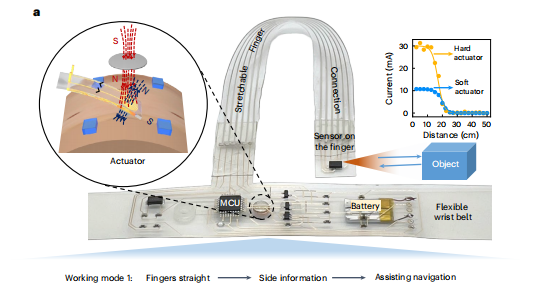
但只有前方和两侧的检测还不够。视障人士的日常生活不只是行走,还包括大量的手部操作,拿起桌上的水杯、按电梯按钮、在超市货架上寻找商品。因此智能手环被赋予了双重身份。当手臂自然下垂时,手环朝向侧面,监测行走时的侧向威胁。而当抬起手臂伸向前方时,手环自动切换模式,变成精确的测距仪。它能告诉使用者手离目标还有多远,什么时候该张开手掌准备抓取。而且系统采用红外深度感知技术,即使在完全黑暗的环境中,系统的性能也丝毫不受影响。
随着AI的技术愈发发达,采用专用AI芯片替代通用处理器可以将功耗降低,仿生视觉传感器的应用也能够进一步提升检测精度,大规模生产会显著降低成本。从更广阔的视角看,这不仅是一项助盲技术。当AI能够实时理解环境并转化为多模态信号时,我们可以相信,它可以帮助更多人,例如老年人防跌倒、司机盲区预警、暗环境作业导航。
20名视障测试者给这套系统打出了79.6分的可用性评分,在5000个同类评测中排名前15%。但比分数更重要的,是他们重新获得的可能性。正如研究团队在论文结尾写道:“这项工作为用户友好的视觉辅助系统铺平了道路,为视障人士提高生活质量提供了新的途径。”
参考文献
Tang, J., Zhu, Y., Jiang, G. et al. Human-centred design and fabrication of a wearable multimodal visual assistance system. Nat Mach Intell 7, 627–638 (2025).
图文简介